
Ein absolutes Basic bei der SEO Optimierung einer Webseite, stellt die Optimierung für die ideale robots.txt dar.
Was ist die robots.txt:
Die Robots Exclusion Protocol (REP) oder robots.txt ist eine Textdatei, um Suchmaschinen Roboter anzuweisen, wie diese crawlen (Webseite durchsuchen) und in der Suchmaschine indexieren (aufnehmen) dürfen.
Diese Textdatei muss immer „robots.txt“ heißen und muss immer im Hauptverzeichnis (Root) der Webseite liegen, siehe Beispiel: http://www.webfreundlich.de/robots.txt
Gründe für die Optimierung der idealen robots.txt:
- Google sucht als ersten bei dem Aufruf einer Webseite nach dieser Datei, was deren Bedeutung unterstreicht
- Manchmal wird eine Webseite für den Google Bot unbewusst ganz oder teilweise gesperrt
- Oft wird eine Webseite an Stellen gecrawlt, welche für den Google Bot Tabu sein sollten und somit wird wertvolles Crawling Budget verschwendet
- Auch falsche robots.txt Einträge werden oft gesehen, welche dann keine Wirkung haben, wie gewünscht
Übersicht der Befehle zur die Optimierung der robots.txt:
Blockieren aller Web-Crawler von allen Inhalten
User-agent: *
Disallow: /
Blockieren Sie eine bestimmte Web-Crawler aus einem bestimmten Ordner
User-agent: Googlebot
Disallow: /verzeichnis-xyz/
Blockieren Sie eine bestimmte Web-Crawler von einer bestimmten Web-Seite
User-agent: Googlebot
Disallow: /verzeichnis-xyz/blockierte-seite.html
Lassen Sie eine spezielle Web-Crawler, um eine bestimmte Webseite besuchen
User-agent: *
Disallow: /verzeichnis-xyz/blockierte-seite.html
User-agent: Googlebot
Allow: /verzeichnis-xyz/blockierte-seite.html
Sitemap Parameter
Sitemap: http://www.webfreundlich.de/sitemap_index.xml
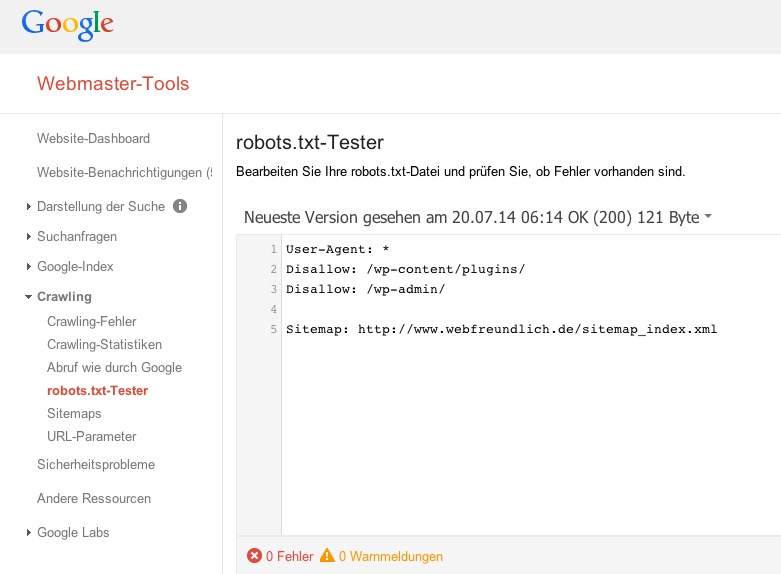
Prüfung der robots.txt auf Fehler
Nutzen Sie die Möglichkeit, Ihre Robots.txt auf Fehler zu prüfen. Hierzu stellt Google in den Google Webmaster Tools ein eigenes Tool zur Verfügung.
Wichtige robots.txt Regeln
- Immer daran denken: die robots.txt kann einer Suchmasche nur das Crawling untersagen, aber nicht die Indizierung!
- Wenn ein Verzeichnis oder eine Datei bereits im Google Index zu finden sind, sollte zuerst das Meta Tag Robots mit den Parametern „noindex, follow“ zur Steuerung Indexierung eingesetzt werden
- Erst wenn ein Verzeichnis oder eine Datei nicht mehr im Google Index zu finden sind, sollte man diese mit der robots.txt auch für das Crawling sperren
- Es ist wichtig zu beachten, dass bösartige Crawler wahrscheinlich die robots.txt völlig ignorieren
- Nur ein „Disallow:“-Zeile wird für jede URL erlaubt
- Jede Subdomain auf einem Root-Domain verwendet eine separate robots.txt-Dateie
- Google und Bing übernehmen zwei Zeichen für spezifische Expressionsmuster Ausgrenzung (* und $) regelmäßig.
- Der Dateiname der robots.txt-und Kleinschreibung. Verwenden Sie „robots.txt“, nicht „Robots.txt“.
Weitere Informationen zur robots.txt:
Die Robots Exclusion Protocol (REP) ist eine Gruppe von Web-Standards, Web-Roboter Verhalten und die Indizierung durch Suchmaschinen zu regulieren. Die REP besteht aus den folgenden:
- Die ursprüngliche REP von 1994, erweitert 1997, die Definition Raupen Richtlinien für robots.txt. Einige Suchmaschinen-Unterstützung Erweiterungen wie URI-Muster (Wild Cards).
- Seine Ausdehnung von 1996 definiert, Indexer-Richtlinien (REP-Tags) für den Einsatz in der Robots-Meta-Element, auch bekannt als „Robots-Meta-Tag.“ Inzwischen Suchmaschinen unterstützen zusätzliche REP-Tags mit einem X-Robots-Tag. Webmaster können REP-Tags im HTTP-Header von Nicht-HTML-Ressourcen, wie PDF-Dokumente oder Bilder anzuwenden.
- Die Microformat rel-nofollow von 2005 definiert, wie Suchmaschinen sollten Links zu behandeln, wo die Ein Element der REL-Attribut enthält den Wert „nofollow“.
Robots Exclusion Protocol Schlagwörter
Zu einer URI, REP-Tags (noindex, nofollow, unavailable_after) steuern insbesondere Aufgaben der Indexer und in einigen Fällen (nosnippet, noarchive, noodp), auch für Abfragen zur Laufzeit einer Suchanfrage angewendet. Anders als bei Raupen Richtlinien, interpretiert jede Suchmaschine REP-Tags anders. Zum Beispiel, wischt sich sogar Google-URL nur Inserate und ODP Verweise auf ihren SERPs, wenn eine Ressource getaggt mit „noindex“, aber manchmal Bing Listen auf ihren SERPs derartige externe Verweise auf URLs verboten. Seit REP-Tags können in META-Elemente von X / HTML-Inhalte sowie in HTTP-Header von einem beliebigen Web-Objekt zugeführt werden, ist der Konsens, dass der Inhalt von X-Robots-Tags sollten widersprüchliche Richtlinien in META-Elemente gefunden stimmen.
Microformats
Indexer-Richtlinien setzen, wie Mikroformate werden Seiteneinstellungen für bestimmte HTML-Elemente überstimmen. Zum Beispiel, wenn eine Seite von X-Robots-Tag heißt es „folgen“ (es gibt keine „nofollow“-Wert), die rel-nofollow-Richtlinie eines bestimmten A-Element (Link), gewinnt.
Obwohl robots.txt fehlt Indexer-Richtlinien, ist es möglich, Indexer Richtlinien für Gruppen von URIs mit serverseitigen Skripts auf Site-Ebene, die X-Robots-Tags, die angeforderten Ressourcen gelten handeln gesetzt. Diese Methode erfordert Programmierkenntnisse und ein gutes Verständnis von Web-Server und das HTTP-Protokoll.
Pattern Matching
Google und Bing sowohl ehren zwei reguläre Ausdrücke, die verwendet werden können, um Seiten oder Unterordnern, die ein SEO will ausgeschlossen identifizieren. Diese beiden Zeichen sind die Stern (*) und das Dollarzeichen ($).
* – Das ist eine Wildcard, die jede Folge von Zeichen repräsentiert, ist
$ -, Die das Ende der URL entspricht
Presse und Information
Die robots.txt-Datei ist öffentlich-bewusst sein, dass eine robots.txt-Datei ist eine öffentlich zugängliche Datei. Jeder kann sehen, welche Abschnitte eines Servers der Webmaster die Motoren blockiert aus. Das bedeutet, wenn ein SEO hat private Anwender Informationen, die sie nicht wollen, dass öffentlich durchsuchbar, werden sie eine sichere Ansatz-wie verwenden sollte als Passwort-Schutz-Besucher aus der Anzeige keine vertraulichen Seiten, die sie nicht indiziert werden wollen zu halten.